멀티쓰레딩 프로그래밍에서 락을 잡는 타이밍이 짧다면 이론적으로 spin lock을 사용하여 busy waiting을 하는 것이 성능에 좋다고 알고 있다.
하지만, 실제로 spin lock으로 효과를 보기 쉽지 않은데, CPU에 이를 위해 pause라는 명령어가 존재한다.
spin lock이라는게 결국 변수의 값이 원하는 값이 될때까지 계속 loop를 돌리는 것인데, pause라는 명령어를 통해 CPU에게 지금 spin loop를 돌고 있다는 힌트를 주고, CPU가 메모리버스 속도 등을 감안해서 변수가 바뀌는데 필요한 최소한의 시간만큼 다음 명령어를 실행하지 않는 것이다.
– 참고 https://software.intel.com/sites/default/files/m/d/4/1/d/8/17689_w_spinlock.pdf (w_spinlock.pdf)
이를 테스트 해보았다.
인텔계열의 CPU에서는 _mm_pause();라는 함수로 pause를 사용 할 수 있다.
- Visual Studio에서는 YieldProcessor(); 라는 매크로 함수도 동일하다.
간단하게 코드를 보면
|
1 2 3 4 5 6 7 8 9 10 11 |
std::atomic<bool> lock; { // spin lock bool exp = false; while (!lock.compare_exchange_strong(exp, true)) { exp = false; _mm_pause(); // __asm pause // YieldProcessor(); } } |
실제로 pause 명령어를 사용했을 때와 안했을 때를 테스트 해봤을 때….
어마어마한 차이가 났다.
테스트 케이스는 I7-6700K CPU (8코어) 에서 8개의 쓰레드에서 스핀락을 걸고, 스핀락이 성공하면 Sleep(0)로 잠깐 휴지기를 주었으며, 시간 측정은 spin-loop 구간만 측정하였다.
결과는…
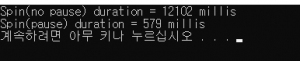
실행할때마다 결과가 다르긴 한데… 10배이상의 차이가….
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 |
#include <atomic> #include <iostream> #include <vector> #include <algorithm> #include <thread> #include <Windows.h> #include <chrono> static constexpr size_t TEST_COUNT = 100000; class Spin { public: Spin() { } ~Spin() { std::cout << "Spin(no pause) duration = " << std::chrono::duration_cast<std::chrono::milliseconds>(_duration).count() << " millis" << std::endl; } void Run() { while (_count < TEST_COUNT) { const auto now = std::chrono::steady_clock::now(); bool exp = false; while (!_lock.compare_exchange_strong(exp, true)) { exp = false; } if (_count++ < TEST_COUNT) { const auto now2 = std::chrono::steady_clock::now(); _duration += (now2 - now); ::Sleep(0); } _lock.store(false); } } private: std::atomic<bool> _lock = { false }; size_t _count = 0; std::chrono::steady_clock::duration _duration = std::chrono::steady_clock::duration::zero(); }; class SpinHint { public: SpinHint() { } ~SpinHint() { std::cout << "Spin(pause) duration = " << std::chrono::duration_cast<std::chrono::milliseconds>(_duration).count() << " millis" << std::endl; } void Run() { while (_count < TEST_COUNT) { const auto now = std::chrono::steady_clock::now(); bool exp = false; while (!_lock.compare_exchange_strong(exp, true)) { exp = false; _mm_pause(); // __asm pause // YieldProcessor(); } if (_count++ < TEST_COUNT) { const auto now2 = std::chrono::steady_clock::now(); _duration += (now2 - now); ::Sleep(0); } _lock.store(false); } } private: std::atomic<bool> _lock = { false }; size_t _count = 0; std::chrono::steady_clock::duration _duration = std::chrono::steady_clock::duration::zero(); }; int main() { constexpr size_t threadCount = 8; { std::vector<std::thread> threads; threads.reserve(threadCount); Spin test; for(size_t i = 0; i < threadCount; ++i) { threads.emplace_back(std::thread(&Spin::Run, &test)); } for (auto& t : threads) { t.join(); } } { std::vector<std::thread> threads; threads.reserve(threadCount); SpinHint test; for (size_t i = 0; i < threadCount; ++i) { threads.emplace_back(std::thread(&SpinHint::Run, &test)); } for (auto& t : threads) { t.join(); } } ::system("pause"); return 0; } |
codemore code
~~~~